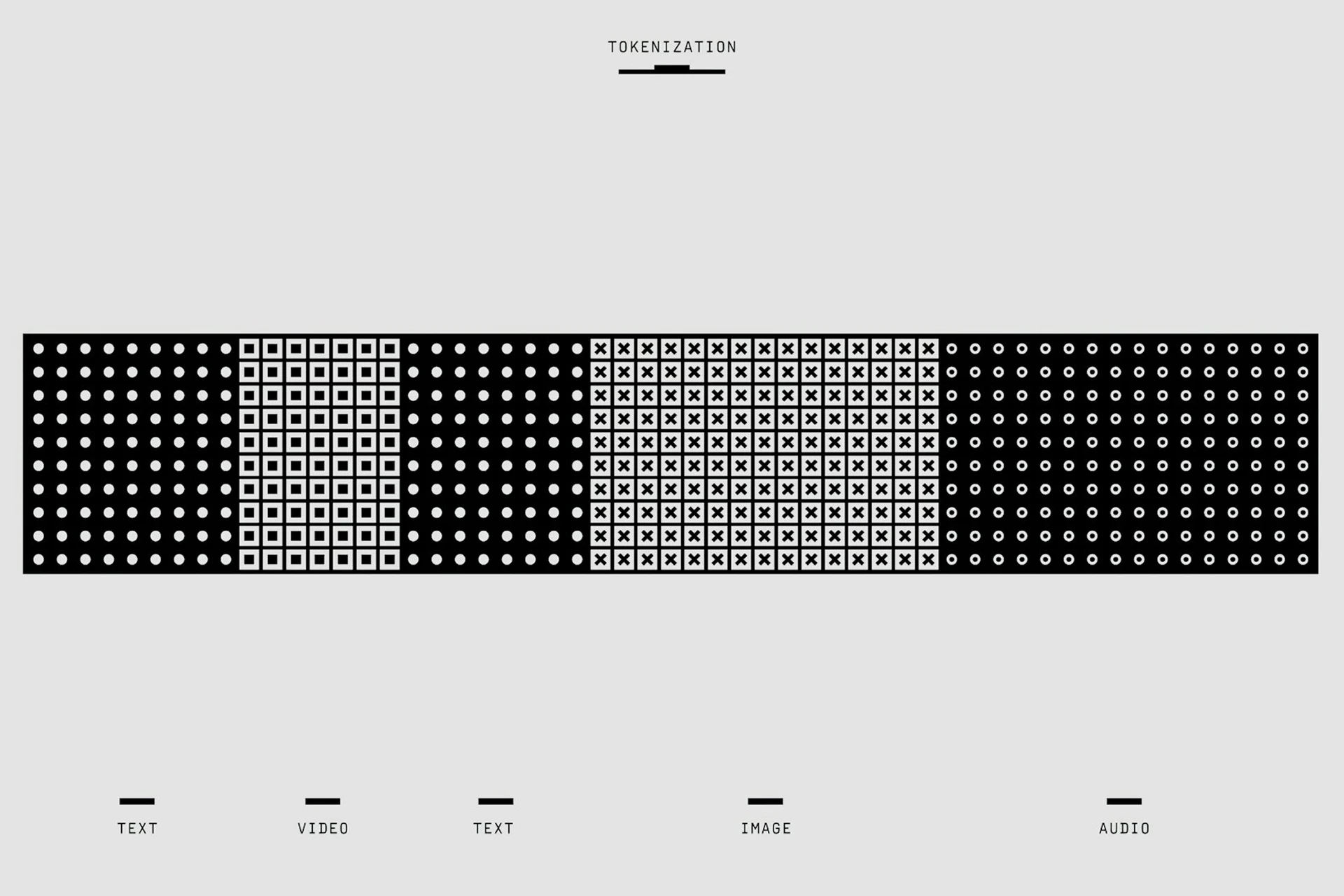
At Anovate, we believe that meaningful AI adoption starts with understanding the fundamentals behind how intelligent systems process language. One of the most critical aspects of this is how models represent and interpret text through tokens, LLM tokenization, and vocabulary.
These concepts define how language models like ChatGPT convert words into data, learn contextual relationships, and generate coherent, human-like responses. In this article, we unpack these ideas through clear explanations and real-world analogies—bridging technical depth with practical understanding for business and technology leaders exploring the impact of AI.
What Is a Token?
At its core, a token is the smallest unit of text that a language model processes to interpret and generate language. It can be a single character, an entire word, or a portion of a word, such as a suffix or prefix. The specific definition depends on the model’s design.
For instance, consider the sentence: “I can’t wait to eat pizza!” A model like the one powering ChatGPT might break this into approximately seven or eight tokens, such as “I”, “ can”, “’t”, “ wait”, “ to”, “ eat”, and “ pizza”. Notice how “can’t” is divided into “ can” and “’t”? This occurs because the model treats contractions or subword units separately to manage linguistic variations effectively. This flexibility is a critical aspect of how AI handles text.
How Does Tokenization Work?
Tokenization refers to the process of dividing text into these individual tokens. It is akin to preparing ingredients for a recipe, slicing bread, cheese, and vegetables into manageable portions before assembling a sandwich. This step allows the AI to transform raw text into a format it can analyze.
Interestingly, in some models, a single token approximates three-quarters of a word. Thus, 100 tokens roughly equate to 75 words. This ratio is particularly useful for estimating context limits or resource usage when interacting with AI systems or developing applications, providing a practical metric for engineers and developers.
What Is Vocabulary in This Context?
Vocabulary represents the complete set of tokens a model recognizes and can work with, functioning as its linguistic dictionary. Rather than consisting solely of words, it includes all possible token combinations, much like a set of ingredients that can be combined to create a wide array of dishes.
For example, some models operate with vocabularies of 32,000 tokens, while others extend to 100,000 or more. This capacity enables them to process multiple languages, colloquial expressions like “cool”, and technical terms such as “neural network”. A larger vocabulary enhances a model’s versatility but also increases its computational demands, a trade-off carefully considered by developers.
Why Language Models Use Tokens (Not Words or Characters)
A common question arises: why not use whole words or individual characters instead of tokens? This is a valid inquiry, and understanding the rationale highlights the efficiency of tokens.
Using whole words would require an extensive vocabulary, potentially hundreds of thousands of entries, accounting for variations like plurals, tenses, and misspellings. This would strain the model’s memory and processing capabilities. Tokens address this by decomposing unfamiliar or complex words into familiar components. For instance, a coined term like “pizzariffic” could be interpreted using “pizza” and “riffic”, avoiding the need for an exhaustive word list.
Conversely, relying on characters alone, such as “p-i-z-z-a”, would result in excessively long sequences. A simple phrase like “I love pizza” could expand into 20 or more units, complicating the model’s ability to grasp context and increasing computational load. Tokens strike a balance by grouping meaningful units like “love” or “pizza” together, optimizing both speed and comprehension.
In essence, tokens offer a compromise: they are more concise than character-based approaches, reducing sequence length, and more manageable than word-based systems, keeping vocabulary sizes practical. This enables language models to handle diverse linguistic tasks efficiently, from casual conversation to multilingual applications.
Conclusion
This article introduced the fundamentals of tokens, tokenization, and vocabulary, key concepts that define how language models process and generate text. Understanding these principles builds a strong foundation for anyone looking to engage more deeply with artificial intelligence and its real-world applications.
We look forward to sharing more insights as we continue exploring the evolving landscape of AI and data intelligence. Share your thoughts in the comments or connect with us to keep the conversation going.