In modern organizations, data is at the center of almost every decision. Yet the path from raw data to insights is rarely simple. Information often flows through dozens of systems, transforming and combining at different stages before it becomes usable. Without discipline, these processes quickly turn messy. Files get updated at the wrong time, dependencies are missed, and teams find themselves chasing down errors in the middle of the night.
This is where Apache Airflow has become a cornerstone for many data-driven companies. Far from being just another scheduling tool, it provides a framework to build, monitor, and manage data pipelines in a way that makes them both reliable and understandable. Instead of duct-taping scripts together and hoping they run in the right order, teams use Airflow to create a clear blueprint for how data should move.
From Cron Jobs to Workflows
Before tools like Airflow, many teams relied on cron jobs and custom scripts to manage data tasks. That approach works fine when there are just a handful of jobs, but it collapses under complexity. Once you have multiple systems feeding each other, it becomes critical to know not only when a job runs but also what it depends on, how failures should be handled, and how to rerun pieces of the process without breaking the whole chain.
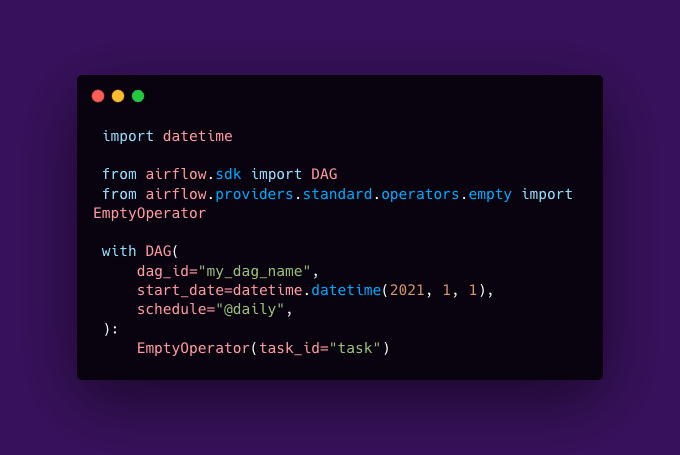
Airflow’s innovation was to treat workflows as code. Instead of managing scattered scripts, you define pipelines as directed acyclic graphs (DAGs). Each node represents a task, and the graph structure defines how tasks depend on each other. This gives a single source of truth for the pipeline and makes dependencies explicit. Anyone looking at the DAG can understand the flow at a glance, and Airflow ensures that tasks run in the right sequence.
Building Reliability Into Pipelines
A major benefit of Airflow is the reliability it introduces. Pipelines can be set with retries, so a temporary glitch does not derail an entire data flow. Failures are logged and surfaced in a web-based UI, making it easier for engineers to troubleshoot. Instead of waking up to find that a critical report failed silently, teams can receive alerts and immediately see where the problem lies.
The ability to backfill is another important feature. If data for the past week failed to process, Airflow can be instructed to rerun the pipeline for that specific range of dates. This is a huge step up from manual reprocessing, which often involves risky workarounds.
By making reliability part of the framework, Airflow allows engineers to focus on improving their data logic rather than firefighting broken jobs. Over time, this reduces operational stress and helps build confidence in the pipelines that support key business decisions.
Scalability and Extensibility
As data needs grow, pipelines often need to run at larger scales or integrate with new systems. Airflow was designed with this in mind. It can distribute workloads across multiple workers, making it possible to process larger datasets without rewriting the orchestration logic. Its plugin system and large library of operators allow integration with cloud services, databases, and external APIs.
This flexibility means Airflow can be used across different environments, from a startup running a handful of ETL jobs to an enterprise with hundreds of interdependent workflows. The same principles apply, regardless of scale, which makes it easier for teams to adopt best practices early and grow into them.
Human-Friendly Monitoring
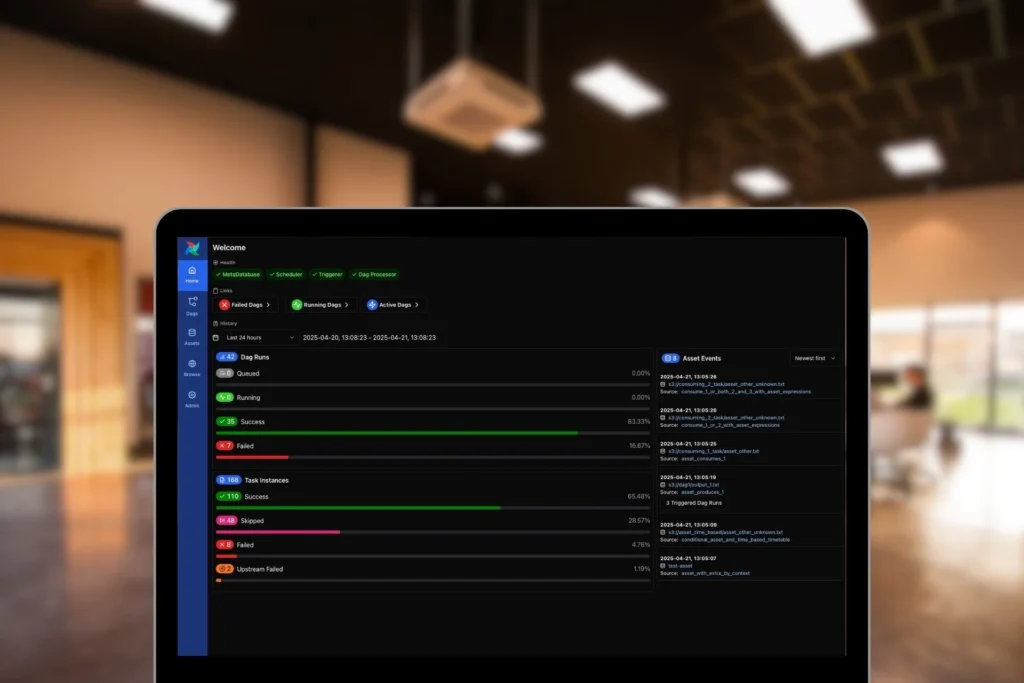
One of the things that makes Airflow approachable is its web UI. Instead of digging through logs to figure out what happened, users can see a visual representation of their DAGs, with color-coded indicators showing the status of each task. Failed tasks stand out immediately, and logs can be accessed with a click.
This visibility reduces the sense of data pipelines as a black box. Stakeholders outside the engineering team can check the UI to see whether a job has completed. Analysts waiting on data no longer need to rely on guesswork; they can see progress directly. By making pipelines more transparent, Airflow strengthens collaboration between technical and non-technical teams.
Why Airflow Matters
In many ways, Airflow has done for data workflows what version control did for software. It turned something fragile and ad hoc into something reproducible and understandable. By codifying pipelines, enforcing dependencies, and providing monitoring, it transformed the way data engineering teams operate.
It also shifted the culture around data. Instead of pipelines being maintained by a few specialists who know the quirks of each cron job, Airflow creates a shared language. Pipelines are code, versioned in repositories, and reviewed like other software. This improves quality and reduces the risk of knowledge silos.
As companies continue to depend on data to guide growth and innovation, reliable orchestration becomes essential. The difference between a data platform that works and one that constantly breaks often comes down to how well the underlying pipelines are managed. Apache Airflow provides a foundation for building these systems with confidence.
Every successful business decision
starts with a reliable pipeline.